Can you compose memory across a HPC cluster? Yes. Yes you can
Note: This article originally appeared on theregister.com, click here to read the original piece.
Dan Robinson Thu 20 Jan 2022 // 16:27 UTC
GigaIO CTO talks up ‘solution that has a lot of what CXL offers’
GigaIO and MemVerge are developing a joint solution to enable memory to be composable across a cluster of servers, addressing one of the thorny issues in high performance computing (HPC) where some nodes may not have enough memory for the tasks in hand, while others may have spare capacity.
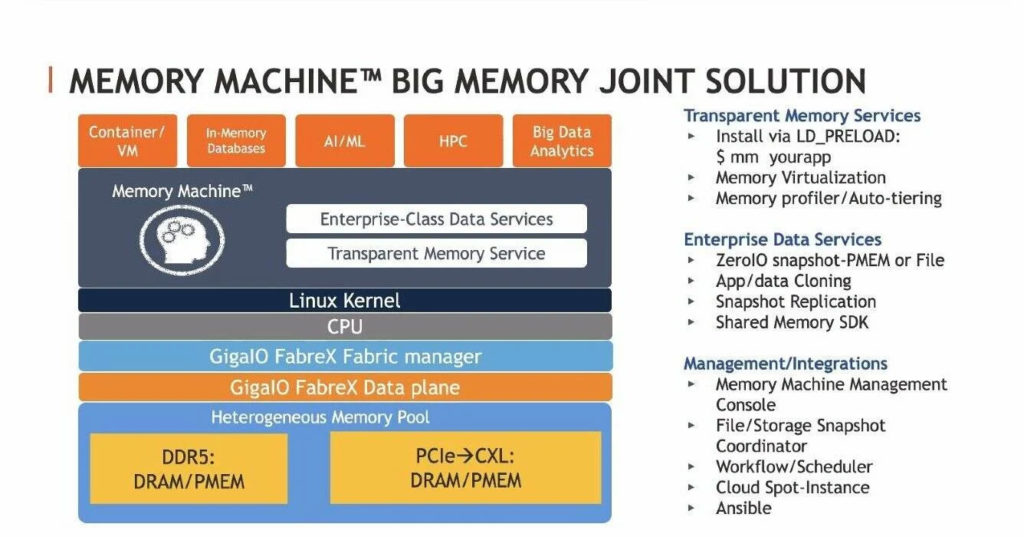
The combined GigaIO-MemVerge stack that supports composable memory
The joint solution, which combines GigaIO’s FabreX interconnect fabric with MemVerge’s memory virtualization platform, was discussed at a Dell Technologies HPC Community online event this week, and anticipates the availability of hardware supporting version 2.0 of the CXL interconnect.
GigaIO’s FabreX is based on PCIe and described by the firm as a rack-scale composable infrastructure solution. It already allows resources such as CPUs, GPUs, FPGAs, ASICs and storage to be orchestrated across a cluster of nodes. The fabric supports direct memory access, enabling direct CPU to GPU data transfers between nodes, for example.
“We can create a system that goes well beyond what one server can handle,” explained Matt Demas, CTO of Global Sales at GigaIO. However, he added that: “Today, everything in the rack – except memory – is composable.”
This is where MemVerge comes in with its Memory Machine software, which acts as an abstraction layer between memory and applications. It virtualizes both DRAM and persistent memory (PMEM) such as Intel’s Optane to create a pool of software-defined memory with transparent tiering that just looks like plain old memory to applications.
The key part to bear in mind is that Intel’s Optane DIMMs are available in higher capacities than standard memory DIMMs, but at half the cost per GB of DDR4. Optane has higher latency than DDR4, but can be useful in providing a larger memory space for applications that require it.
“What is the biggest issue in hardware utilisation?” asked Demas. “It’s often down to not having the right amount of memory, either too much or running out.”
The combination of FabreX and MemVerge “will allow us to compose memory to some applications, and the application won’t know anything about that,” he added, meaning that applications will simply see a continuous memory space, even if some of that memory is physically located in another node.
“You can use DRAM or PMEM, but also potentially re-use older servers that might otherwise have been disposed of, but you can utilise their memory,” Demas said.
Bernie Wu, veep of business development at MemVerge, said that the company’s Memory Machine software “runs above the kernel, slides right in underneath the HPC apps,” to provide a transparent memory service, intercepting memory calls and providing virtualized memory.
Memory Machine works its magic by profiling memory calls from applications, so that it can move data around between DRAM and PMEM to deliver the optimal performance, while using PMEM to extend the available memory to an application.
“A lot of HPC apps already use a lot of memory, and we found can greatly improve performance by keeping stuff in persistent memory,” Wu said. “Sometimes with PMEM, customers want to cut the costs of DRAM, and in some instances we have found we can get comparable performance to DRAM,” he added.
Another feature that Memory Machine already supports is memory checkpoints for distributed HPC applications.
- Final PCIe 6.0 specs unleashed: 64 GTps link speed incoming… with products to follow in 2023
- Europe completes first phase of silicon independence project
- Graviton 3: AWS attempts to gain silicon advantage with latest custom hardware
- DRAM, it stacks up: SK hynix rolls out 819GB/s HBM3 tech
“A lot of apps were not intended to be long running or fault tolerant, but we can provide transparent checkpointing of the entire state of the app for restarting. We can also move [an application] to another node if rebalancing is needed,” Wu said.
Demas said that the combination of GigaIO and MemVerge is “creating a solution that has a lot of what CXL offers,” and that with CXL 2.0 it will “just get better and give a solution that everybody is asking for.”
CXL 2.0 is based on PCIe 5.0, like the existing CXL 1.0, but adds support for a switched fabric that allows a host server to connect to resources on multiple other devices. ®
View source version on theregister.com: https://www.theregister.com/2022/01/20/compose_memory_across_a_hpc/


")