Crafting A DGX-Alike AI Server Out Of AMD GPUs And PCI Switches
Note: This article originally appeared on nextplatform.com, click here to read the original piece.
Not everybody can afford an Nvidia DGX AI server loaded up with the latest “Hopper” H100 GPU accelerators or even one of its many clones available from the OEMs and ODMs of the world. And even if they can afford this Escalade of AI processing, that does not mean for a second that they can get their hands on the H100 or even “Ampere” A100 GPUs that are part and parcel of this system given the heavy demand for these compute engines.
As usual, people find economic and technical substitutes, which is how a healthy economy works, driving up the number of alternatives and driving down the costs across all of those alternatives thanks to competition.
So it is with the SuperNode configurations that composable fabric supplier GigaIO has put together with the help of server makers Supermicro and Dell. Rather than using Nvidia GPUs, the GigaIO SuperNodes are based on cheaper AMD “Arcturus” Instinct MI210 GPU accelerators, which plug into PCI-Express slots and do not have the special sockets that higher end GPUs from Nvidia, AMD, or Intel require – SXM4 and SXM5 sockets for the A100 and H100 GPUs from Nvidia and OAM sockets from AMD and Intel. And rather than using NVLink interconnects to lash together the Nvidia A100 and H100 GPU memories into a shared memory system or the Infinity Fabric interconnect from AMD to lash together the memories of higher-end Instinct MI250X GPUs, the SuperNode setup makes use of PCI-Express 4.0 switches to link the GPU memories to each other and to the server host nodes.
This setup has less bandwidth than the NVLink or Infinity Fabric interconnects, of course, and even when PCI-Express 5.0 switches are available this will still be the cast – something we lamented about on behalf of companies like GigaIO and their customers recently. We still maintain that PCI-Express release levels for server ports, adapter cards, and switches should be made available in lockstep in hardware rather than having a tremendous lag between the servers, the adapters, and the switches. If composable infrastructure is to become commonplace, and if PCI-Express interconnects are the best way to achieve this at the pod level (meaning a few racks of machines interlinked), then this seems obvious to us.
Neither GigaIO nor its customers have time to wait for all of this to line up. It has to build clusters today and bring the benefits of composability to customers today, which it can do as we have shown in the past with case studies and which those links refer to. Most importantly, composability allows for the utilization of expensive compute engines like GPUs to be driven higher as multiple workloads running on clusters change over time. As hard as this is to believe – and something that was shown at the San Diego Supercomputing Center in its benchmarks – you can use less performant GPUs or fewer of them, drive up their utilization, and still get faster time to results with composable infrastructure than you can with big, beefy GPU iron.
The GigaPod, SuperNode, and GigaCluster configurations being put together by GigaIO are a commercialization of this idea, and it is not limited to AMD MI210 GPUs. Any GPU or FPGA or discrete accelerator that plugs into a PCI-Express 4.0 or 5.0 slot can be put into these configurations.
A GigaPod has from one to three compute nodes based on two-socket servers employing AMD’s “Milan” Epyc 7003 processors, but again, there is nothing that ties GigaIO or its customers from using other CPUs or servers other than those from Dell or Supermicro. This is just the all-AMD configuration that has been certified to be sold as a single unit to customers.
The GigaPod has a 24-port PCI-Express switch that is based on the Switchtec Gen 4.0 PCI-Express switch ASIC from Microchip Technology. (We profiled the Microchip Gen 5.0 Switchtec ASICs here, and hopefully they will start shipping in volume soon.) GigaIO uses PCI-Express adapter ASICs from Broadcom to attach servers, storage enclosures, and accelerator enclosure to this switching backbone, which its FabreX software stack can disaggregate and compose on the fly. The GigaPod has sixteen accelerators, and the CPUs and GPUs are provisioned using Bright Cluster Manager from Bright Computing, which was bought by Nvidia in January 2022.
The SuperNode configuration that GigaIO has been showing off for the past several months is a pair of interlinked GigaPods, and it looks like this:
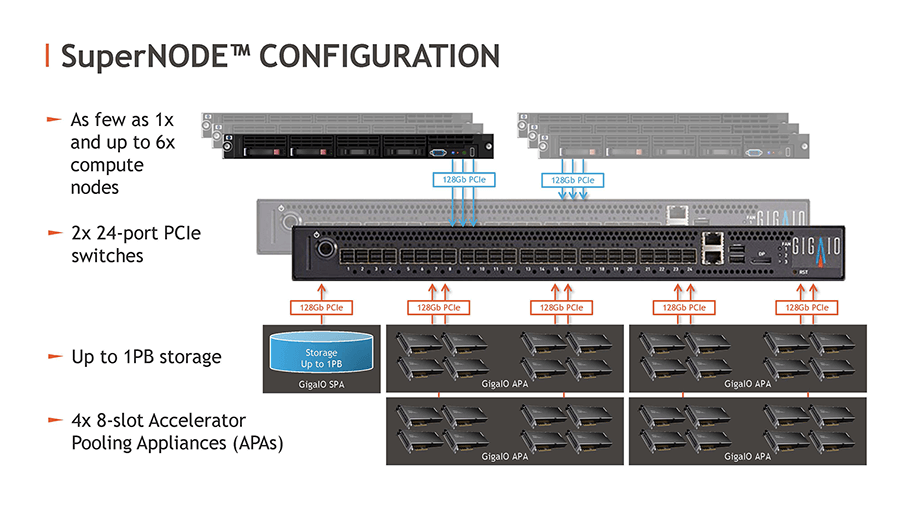
This gives you a better idea of what the configuration looks like. In this case, there are 32 AMD Instinct MI210 accelerators in four GigaIO Accelerator Pool Appliance (APA) enclosures, which link into a pair of 24-port PCI-Express 4.0 switches. This configuration also has up to a pair of GigaIO’s Storage Pool Appliances (SPAs), each of which has 32 hot-swappable NVM-Express flash adapters yielding 480 TB of raw capacity. Each server has a 128 Gb/sec link into the switches and each pair of accelerators has 64 Gb/sec of bandwidth into the switches. The storage arrays have a 128 Gb/sec pipe each, too. Technically, this is a two-layer PCI-Express fabric.
If you need more than 32 GPUs (or other accelerators) in a composable cluster (one that would allow for all of the devices to be linked to one server if you wanted that), then GigaIO will put together what it calls a GigaCluster, which is a three-layer PCI-Express 4.0 switch fabric that has a total of 36 servers and 96 accelerators.
The question, of course, is how does this PCI-Express fabric compare when it comes to performance to an InfiniBand cluster that has PCI-Express GPUs in the nodes and no NVLink and one that has NVLink fabrics within the nodes or across some of the nodes and then InfiniBand across the rest of the nodes (or all of them) as the case may be.
We’re not going to get that direct comparison that we want. Except anecdotally.
“I won’t claim these as exhaustive studies, but we have found a number of cases where people have interconnected four or eight GPU servers together across InfiniBand or across Ethernet,” Alan Benjamin, co-founder and chief executive officer of GigaIO, tells The Next Platform. “And generally, when they scale within that four GPUs or within that eight GPUs inside of the node, the scale is pretty good – although in most cases they’re scaling it at a 95 percent number, not a 99 percent number. But when they go from one box to multiple, separate boxes, there’s a big loss and it typically gets cut in half. What we’ve seen is that if a machine has eight GPUs that are running at an 80 percent of peak scale, when they go to ninth GPU in a separate box, it drops to 50 percent.”
This is why, of course, Nvidia extended the NVLink Switch inside of server nodes to an NVLink Switch Fabric that spans 32 nodes and 256 GPUs in a single memory image for those GPUs, which Nvidia calls a DGX H100 SuperPod. And it is also why GigaIO is pushing PCI-Express as a better fabric for linking together large numbers of GPUs and other accelerators together in a pod.
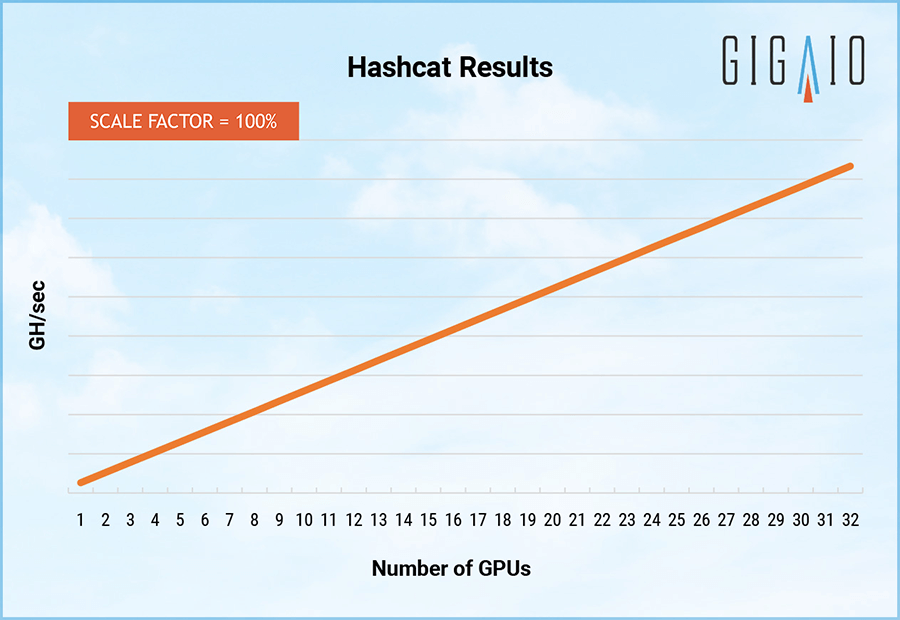
To give a sense of how well this PCI-Express switch interconnect running FabreX works, GigaIO tested two workloads on the AMD-based systems: ResNet50 for image recognition and the Hashcat password recovery tool. Like EDA software, Hashcat dispatches work to each GPU individually and they do not have to share data to do their work, and thus, the scaling factor is perfectly linear:
For ResNet50, says Benjamin, the GPUs have to share work and do so over GPUDirect RDMA, and there is about a 1 percent degradation for each added GPU to a cluster. So at 32 GPUs, the scale factor is only 70 percent of what perfect scaling would be. This is still a heck of a lot better than 50 percent across nodes that interconnect with InfiniBand or Ethernet.
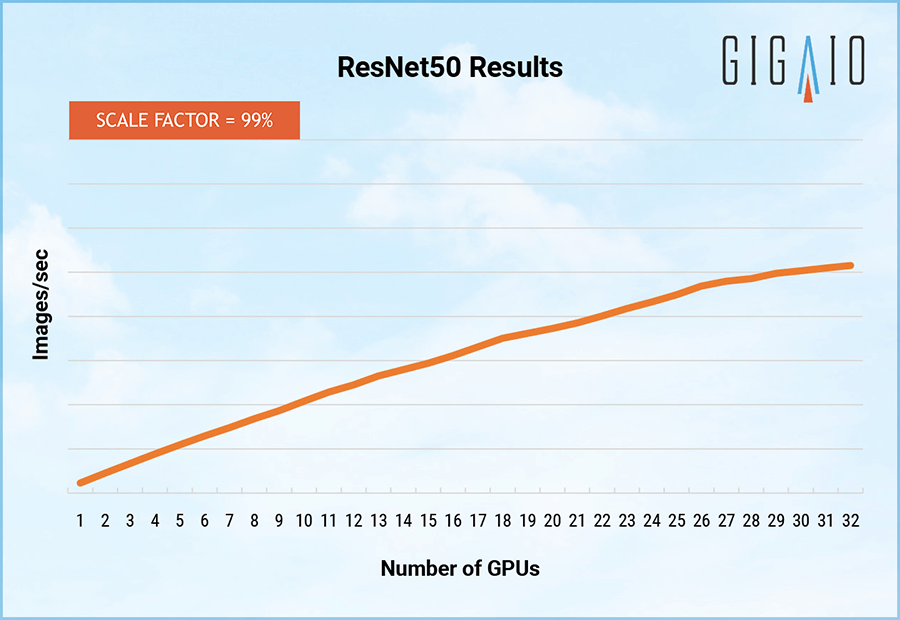
Of course, InfiniBand and Ethernet can scale a lot further if that is something your workloads needs. But if you need 96 or fewer GPUs in a single image, then the GigaCluster approach looks like a winner. And with PCI-Express 5.0 switches, which in theory could have twice as many ports at the same speed, you could scale to 192 GPUs in an image – and with a memory and compute footprint that could be diced and sliced downwards as needed.
One other neat thing. Moritz Lehman, the developer of the FluidX3D computational fluid dynamics application, got a slice of time on the GigaIO SuperNode with 32 MI210 GPUs and showed off a test on LinkedIn where he simulated the Concorde for 1 second at 300 km/h landing speed at 40 billion cell resolution. This simulation took 33 hours to run, and on a desktop workstation using commercial CFD software that Moritz did not name, he claimed it would take years to run the same simulation. So, at the very least, the SuperNode makes one hell of a workstation.
View source version on nextplatform.com: https://www.nextplatform.com/2023/08/15/crafting-a-dgx-alike-ai-server-out-of-amd-gpus-and-pci-switches/


")