GigaIO’s New SuperNode Takes-off with Record Breaking AMD GPU Performance
Note: This article originally appeared on hpcwire.com, click here to read the original piece.
By Doug Eadline
The HPC users dream is to keep stuffing GPUs into a rack mount box and make everything go faster. Some servers offer up to eight GPUs, but the standard server usually only offers four GPUs slots. Fair enough, using four modern GPUs offers a significant amount of HPC heft, but can we go higher? Before we answer that question, consider a collection of eight servers each with four GPUs, for a total of 32 GPUs. There are ways to leverage all these GPUs for one application by using MPI across servers, but many times this is not very efficient. In addition, shared computing environments often have GPU nodes that may sit idle because they are restricted to GPU-only jobs leaving the CPUs and memory unavailable for any work.
Stranded Hardware
In the past, a server with a single socket processor, moderate amount of memory, and a single GPU were much more granular than today’s systems. This granularity allowed for more effective resource application. As servers have packed in more hardware (i.e., large memory multi-core nodes with multiple GPUs) the ability to share resources becomes a bit trickier. A four-GPU node server works great, but it may be used exclusively for GPU jobs and otherwise sit idle. The large granularity of this server means an amount of memory and CPUs may be stranded from use. Simply put, packing more memory, cores, and GPUs into a single server may reduce the overall cost, but for HPC workloads it may end up stranding a lot of hardware over time.
Composable Hardware
The “stranded” hardware situation has not gone unnoticed and Compute Express Link™ (CXL™) was established to help with this trend. The CXL standard, which is rolling out in phases, is an industry-supported Cache-Coherent Interconnect for Processors, Memory Expansion and Accelerators. CXL technology maintains memory coherency between the CPU memory space and memory on attached devices, which allows resource sharing for higher performance, reduced software stack complexity, and lower overall system cost.
While CXL is not quite available yet, one company, GigaIO, does offer CXL capabilities today. Indeed, GigaIO has just introduced a single-node supercomputer that can support up to 32 GPUs. These GPUs are visible to a single host system. There is no partitioning of the GPUs across server nodes, the GPUs are fully usable and addressable by the host node. Basically, GigaIO offers a PCIe network called FabreX™ that creates a dynamic memory fabric that can assign resources to systems in a composable fashion.
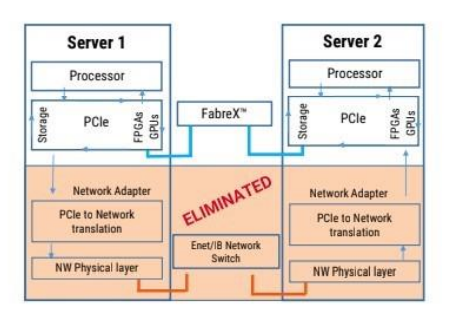
Using the FabreX technology, GigaIO demonstrated 32 AMD Instinct MI210 accelerators running in a single-node server. Available today, the 32-GPU engineered solution, called SuperNODE, offers a simplified system capable of scaling multiple accelerator technologies such as GPUs and FPGAs without the latency, cost, and power overhead required for multi-CPU systems. The SuperNODE has the following benefits over existing server stacks:
- Hardware agnostic — use any accelerator including GPU or FPGAs
- Connects up to 32 AMD Instinct ™ GPUs or 24 NVIDIA A100s to a single node server
- Ideal to dramatically boost performance for single node applications
- The simplest and quickest deployment for large GPU environments
- Instant support through TensorFlow and PyTorch libraries (no code changes)
As noted by Andrew Dieckmann, corporate vice president and general manager, Data Center and Accelerated Processing, AMD, “The SuperNODE system created by GigaIO and powered by AMD Instinct accelerators offers compelling TCO for both traditional HPC and generative AI workloads.”
Benchmarks Tell the Story
GigaIO’s SuperNODE system was tested with 32 AMD Instinct MI210 accelerators on a Supermicro 1U server powered by dual 3rd Gen AMD EPYC™ processors. As the following figure shows two benchmarks, Hashcat and Resnet50, were run on the SuperNODE.
- Hashcat: Workloads that utilize GPUs independently, such as Hashcat, scale perfectly linearly all the way to the 32 GPUs tested.
- Resnet 50: For workloads that utilize GPU Direct RDMA or peer-to-peer, such as Resnet50, the scale factor is slightly reduced as the GPU count rises. There is a one percent degradation per GPU, and at 32 GPUs, the overall scale factor is 70 percent.

These results demonstrate significantly improved scalability compared to the legacy alternative of scaling the number of GPUs using MPI to communicate between multiple nodes. When testing a multi-node MPI model, GPU scalability is reduced to 50 percent or less.
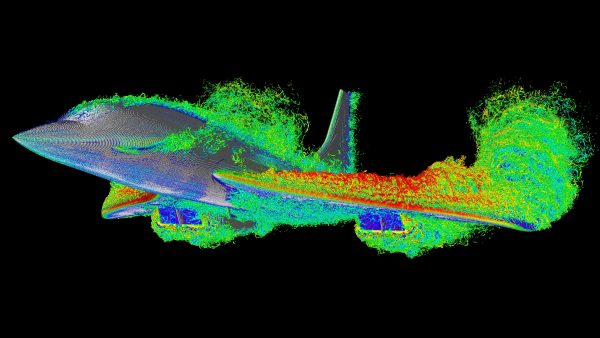
CFD Takes Off on the SuperNode
Recently, Dr. Moritz Lehmann posted on his experiences using the SuperNODE for a CFD simulation on X/Twitter. The incredible videos are viewable on X/Twitter and available on YouTube
Over the course of a weekend, Dr Lehmann tested FluidX3D on the GigaIO SuperNODE. He produced one of the largest CFD simulations ever for the Concorde, flying for one second at 300km/h (186 m/h), using 40 billion cells of resolution. The simulation took 33 hours to run on 32 AMD Instinct MI210 GPUs and 2TB VRAM housed in the SuperNODE. Dr Lehmann explains, “Commercial CFD would need years for this, FluidX3D does it over the weekend. No code changes or porting were required; FluidX3D works out of the box with 32-GPU scaling on AMD Instinct and an AMD Server.”
More information on the GigaIO SuperNODE test results can be found here.
View source version on hpcwire.com: https://www.hpcwire.com/2023/08/10/gigaios-new-supernode-takes-off-with-record-breaking-gpu-performance/


")