GigaPod Solutions
Rack-Scale Computing Made Simple

Compute Outside The Box
GigaIO’s FabreX™ dynamic memory fabric delivers on the promise of rack-scale computing by breaking the server chassis barrier and disaggregating rack components into pools of resources.
Components within a rack and beyond can then be shared and composed on the fly, based on the needs of individual workloads, by integrating compute and GPU acceleration I/O into a single-system dynamic fabric, using standard PCI Express (PCIe) technology. All the resources needed can be optimized for each application, and scaled from the basic GigaPods™ to GigaClusters™ to deliver on the promise of the agility of the cloud at a fraction of the cost.

FabreX dynamic memory fabric enables true rack-scale and accelerated computing, breaking the constraints of the server box to make the entire rack the unit of compute. That is only feasible with FabreX, because all end points and servers within the rack can finally be connected with native PCIe (and CXL in the future), just as if they were still “inside the box”. There is no need for another computational network inside the rack, FabreX can run MPI and RDMA traffic over native PCIe, for the lowest possible latency and highest effective bandwidth. Now your “server” is the entire rack – but how would you go about deploying a FabreX system to gain the performance, flexibility and agility of true rack-scale computing? The easiest way is with our Engineered Solutions, GigaPods and GigaClusters.

The Basic Building Block: A GigaPod™
The GigaPod is the basic element from which you can build a variety of configurations based on your needs for HPC/AI workloads. It is a fully Engineered Solution, with a number of options available for you to tune the GigaPod to best meet your needs.
Because the FabreX platform is completely vendor agnostic, you keep your freedom of choice by selecting your preferred accelerator brand and type – or mix and match accelerators to enable your users to select the precise one needed for a particular workload.
While some specific servers will have limitations in terms of the amount of resources their BIOS will recognize, with the GigaPod Engineered Solutions, GigaIO has worked closely with server manufacturers to optimize certain servers to enable an enormous range of composable options. In addition, you can scale to larger fabric sizes with extended composition, utilizing GigaIO’s unique ability to network servers together over the same PCIe fabric (CXL in the future), so their resources can easily be shared across several nodes.
The example below of a GigaPod includes a switch and two Accelerator Pooling Appliances (APAs) in which you can insert a variety of GPU or FPGA types: they could be all the same accelerators, or for example half AI training and half visualization (or inferencing) GPUs. Compute servers can access all the accelerator resources and expanding on this flexibility, storage servers offer their NVMe storage media as resource pools to all the compute servers in the fabric.
The pooled resources can be composed to match your specific workload, and recombined if needed in a different configuration for the next workflow, using one of our off-the-shelf orchestration software options, or from our Command Line Interface (CLI) if you prefer writing your own scripts.
GigaPods can be configured in a number of ways depending on your needs, whether more storage, more accelerators, or a variety of components. Outfit your APAs with the latest GPUs, a mixture of GPUs, FPGAs, ASICs, DPUs and other accelerators, or combine them all together. You get the flexibility and agility of the cloud, but with the security and cost control of your own on-prem infrastructure.
Scale up to the GigaCluster™
With the complexity of AI models doubling every six months, you need the ability to easily expand your training capability as your model complexity grows. For ease of expansion when your AI workflow demands more resources than can be orchestrated in a single GigaPod, simply combine additional GigaPods via FabreX (PCIe / CXL) to create GigaClusters™.
All the resources inside the entire GigaCluster are connected by the FabreX dynamic memory fabric, transforming the entire GigaCluster into one single unit of compute, where all components communicate over native PCIe (or CXL in future versions) for the lowest possible latency and highest performance.
The First 32 Accelerators AI Node
One of the most exciting configurations of a GigaPod is a SuperNODE: up to 32 accelerators connected to a single server for the most demanding AI workloads, which can also be distributed across up to 6 servers when workloads require fewer accelerators.
Expand The Possibilities With Custom Configurations
If the GigaPod architecture does not meet your needs, FabreX is an open platform built upon industry standards that can be customized.
GIVE FLEXIBILITY TO YOUR HGX DEPLOYMENTS
To create an incredibly powerful compute cell, combine together the power of several NVIDIA™ HGX-based servers, connected over FabreX with NCCL or RCCL rings. You can also use FabreX to add FPGAs or other types and brands of accelerators to your DGX: add an Accelerator Pooling Appliance and mix and match FP32 and FP64 GPUs, DPUs, FPGAs, etc., depending on the optimum device for the accelerated compute task at hand.

MASSIVE STORAGE FOR MASSIVE DATA
You can choose to optimize for high computational efficiency, with up to 640 CPU cores, or you might prefer to create a very large capacity NVMe-oF storage server as shown below with 3PB of storage.
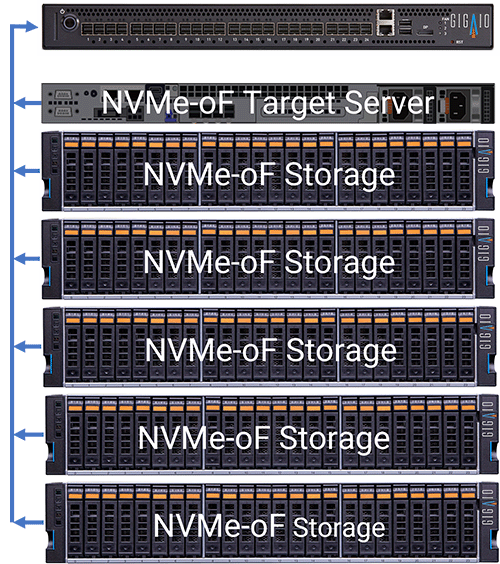
Scale-Out with Custom Topologies
For maximum scalability of data center resources within a single PCIe/CXL fabric, we can use typical scale-out topologies such as leaf and spine or dragonfly, and build custom topologies.
The example below shows a novel way for universities to teach advanced artificial intelligence engineering while keeping within their budget, yet at the same time giving their students access to the latest and greatest in terms of infrastructure components.
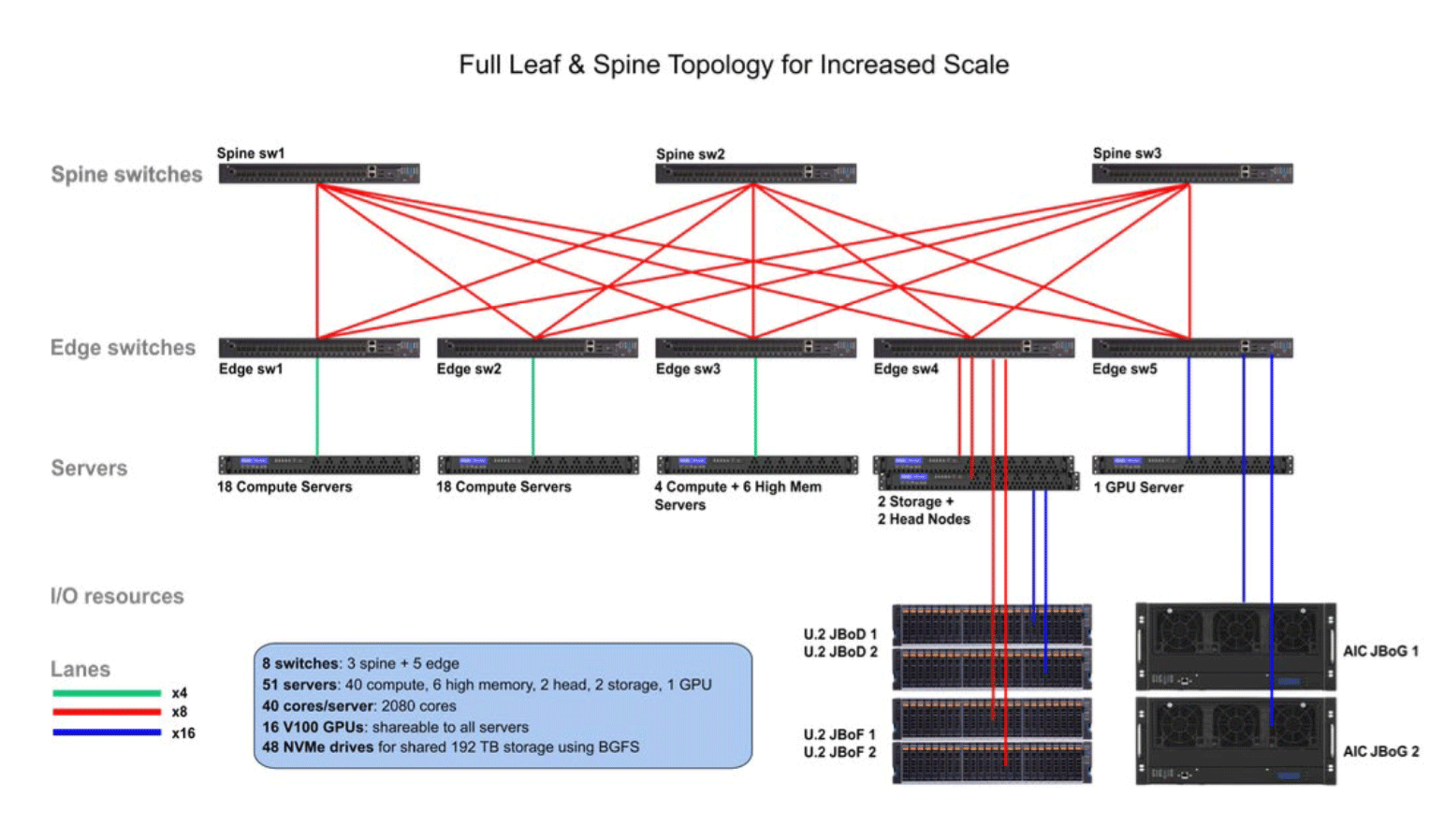
For more details on GigaPods, consult the GigaPod Data Sheet.
To explore custom solutions, talk to an Expert at GigaIO.