(Click title above for PDF download)
Introduction
Nowadays, numerical simulation has played a vital role in analyzing and assessing the earthquake and its effects. Storage I/O performance and network bandwidth have not kept pace with the growth of computing power; as a result, post-processing has become a bottleneck to end-to-end simulation performance. One approach to solving this performance imbalance is to reduce the amount of output data by implementing in-situ visualization, which constructs the visualization concurrent with the simulation [1]. In this paper, we propose a software named “awp-odc-insitu” that is based on the well-known seismic simulation software “awp-odc-os” [2]. The paper describes the objective of implementing in-situ visualization functionality within “awp-odc-os” by employing the open-source data analysis and visualization application “ParaView” and its in-situ library “ParaView Catalyst” [3,4]. Moreover, the paper discusses the functionality and analyzes the performance and efficiency of the awpodc-insitu code to demonstrate the code is of potential use in practical seismic research.
Method
“ParaView” can be easily used to integrate post-processing and/or visualization along with distributed seismic simulation [3]. The original workflow of the “awp-odc-os” software was changed in order to add the in-situ visualization functionality. The modified workflow of our “awp-odc-insitu” software is shown in Figure 1. Before a simulation starts, the “awp-odc-os” software will create an I/O buffer in main memory, for storing data for multiple output iterations. For each output iteration, the CPU downloads the output data from the GPU and saves it in the I/O buffer. Whenever the I/O buffer is full, the CPU outputs the data to storage in binary format with MPI-IO and empties the I/O buffer for the following output iterations. As for our “awp-odcinsitu” implementation, we discard the I/O buffer because we want to visualize the result in real time rather than buffering it in memory. For each output iteration, the CPU still downloads the output data from the GPU, but the output data is sent to the co-processing adaptor. The adaptor is created to call the ParaView co-processing library which maps the output data into VTK data structures and passes the VTK dataset to the ParaView [4].

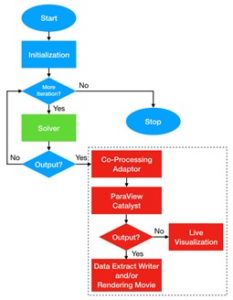
Figure 1. (a) Workflow for “awp-odc-os” software, (b) Workflow for “awp-odc-insitu” software.
ParaView provides three main output options: the data extract writers, the live visualization, as well as the movie rendering. We prepared generalized Catalyst co-processing python scripts for all three options so users can use the proper script to implement its corresponding function. The data extract writer script will save the output data in the form of a series of “Parallel VTK Unstructured Grid (pvtu)” files, which can be opened and viewed directly from the ParaView GUI. The live visualization script sends the output data directly to Paraview so the user can view the data in real-time with the ParaView GUI. The movie rendering script
Results and Discussion
We benchmarked our “awp-odc-instu” code on the “rincon” machine which utilizes the GigaIO FabreX solution. The connections between compute, storage and application accelerator resources in the GigaIO FabreX network are implemented with the rugged, packetized communication protocol of industry-standard PCI Express (PCIe). The specific configuration comprises a Supermicro 5018R-M 1U server with a Xeon E5-2680 v4 @ 2.4GHz (16 cores) with128GB of memory. There are three PCIe Gen 3 x16 connections between the FabreX AIC resources boxes; each connecting four NVidia GTX 1080 Ti GPUs for a total of 12 GPUs.
We performed a weak-scaling test to compare the performance and efficiency between the “awp-odc-insitu” software and the “awp-odc-os” software. The workload on each GPU is 512x512x256 grid points for a total 2000 iterations. Both codes output the ground velocity vectors every 100 iterations. The performance and efficiency benchmark results are shown in Table 1 and Table 2, respectively. For the “awp-odc-insitu” code, as we mentioned above, the “grid” mode outputs in the “pvtu” format, the “movie” mode outputs one frame of top-view image in “png” format, and the “live” mode outputs the data directly to the ParaView GUI instead of saving the data to storage. As for the “awp-odc-os” code, the “binary” mode outputs the data
Table 1. parallel performance comparison between “awp-odc-insitu” and “awp-odc-os”. (unit: GFLOP/s)
|
software |
output |
1x GPU |
2x GPUs |
4x GPUs |
8x GPUs |
12x GPUs |
|
awp-odc-insitu |
grid |
252.31 |
497.68 |
965.93 |
1834.51 |
2362.78 |
|
movie |
203.63 |
400.31 |
811.74 |
1475.61 |
2101.01 |
|
|
live |
257.61 |
505.71 |
978.46 |
1867.11 |
2611.42 |
|
|
awp-odc-os |
binary |
244.58 |
485.64 |
942.47 |
1815.55 |
2393.02 |
|
no-output |
247.68 |
493.05 |
978.13 |
1940.51 |
2673.61 |
Table 2. parallel efficiency comparison between “awp-odc-insitu” and “awp-odc-os”. (unit: %)
|
software |
output |
1x GPU |
2x GPUs |
4x GPUs |
8x GPUs |
12x GPUs |
|
awp-odc-insitu |
grid |
100.00 |
98.62 |
95.71 |
90.89 |
78.04 |
|
movie |
100.00 |
98.29 |
99.66 |
90.58 |
85.98 |
|
|
live |
100.00 |
98.15 |
94.96 |
90.60 |
84.48 |
|
|
awp-odc-os |
binary |
100.00 |
99.28 |
96.34 |
92.79 |
81.54 |
|
no-output |
100.00 |
99.54 |
98.73 |
97.94 |
89.96 |
From the results shown in Table 1, it can be seen that “awp-odc-insitu” achieved parallel performance and efficiency very close to the “awp-odc-os” implementation. Taking the largest 12x GPU tests as an example, the “grid” mode of “awp-odc-insitu” obtains a performance of 2362.78 GFLOP/s which is very close to the “binary” mode of “awp-odc-os” code at 2393.02 GFLOP/s. The “movie” mode of our “awp-odc-insitu” only achieved 2101.01 GFLOP/s. However, this performance is also acceptable if we consider the output file size of this mode is only 145 KB, which is 444x smaller than the output file size in the “binary” mode of “awp-odcos” code. When we compare the “live” mode with the “no-output” mode, we found that we implemented the live visualization with a very small overhead, from 2673.61 GFLOP/s to 2611.42 GFLOP/s. Moreover, the parallel efficiency results in Table 2 shows that our “awpodc-insitu” code obtains very close scalability comparing with the highly optimized “awp-odcos” code.obtains very close scalability comparing with the highly optimized “awp-odcos” code.
Conclusions and Future Works
In this work, we developed the “awp-odc-insitu” code to provide in-situ visualization functionality for the “awp-odc-os” seismic simulation software. With in-situ visualization, researchers can reduce the usage of storage and improve the post-processing efficiency. To verify the parallel performance and efficiency of our code, we also ran some benchmarks using this software on a multiple-GPU machine and the results show that our in-situ implementation obtains expected performance and efficiency. In the future, we plan to continue optimizing and tuning our code on a larger distributed system like Comet from San Diego Supercomputer Center, so that our “awp-odc-insitu” could be a practical tool for petascale and even exascale supercomputers.
NVMe-oF maintains NVMe architecture and software consistency across fabric designs, providing the benefits of NVMe regardless of fabric type or the type of nonvolatile memory utilized by the storage target. It is anticipated that there will be full integration of NVME-oF into the NVMe specification in 2020.
References
- Kageyama, Akira, and Tomoki Yamada. “An approach to exascale visualization: Interactive viewing of in-situ visualization.” Computer Physics Communications 185.1 (2014): 79-85.
- Roten, Daniel, et al. “High-frequency nonlinear earthquake simulations on petascale heterogeneous supercomputers.” Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE Press, 2016.
- Ayachit, Utkarsh, The ParaView Guide: A Parallel Visualization Application, Kitware, 2015, ISBN 978-1930934306
- Ayachit, Utkarsh, et al. “Paraview catalyst: Enabling in situ data analysis and visualization.” Proceedings of the First Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization. ACM, 2015.