
Cloud Repatriation, 2022’s Tech Trend of the Year
Cloud Repatriation Has Become a Thing in 2022
A funny thing has been happening lately when our staff have ventured out to the far reaches of the trade show circuit. They are approached by organizations desperately looking to repatriate their workloads from the cloud back to on-prem. Why? After a few years of running in the cloud, they say their costs are simply too high to be sustainable. Shocking huh?
It’s definitely a thing. Venture Beat recently published the results of a survey showing that 81% of IT teams have been directed to either reduce or halt cloud spending.
But Why Are So Many Seeking out GigaIO for Repatriation?
These organizations tell us they have leaned heavily into GPUs for their workloads, so when they bring them back in-house, they want to pack as many GPUs into a rack as possible to optimize their data center footprint and power envelope – again to keep their costs down. And they typically know those workloads very well. They have come to know the exact ratio of CPU, GPU, RAM, storage, and interconnect needed to make their workloads sing – and they know that only one company has the technology that can deliver on their vision – GigaIO.
Not all organizations know their workloads this well, but the ones that do are the ones that are seeking GigalO out to help them. What’s more, they want to make sure those GPUs are fully utilized, and they want the flexibility to use whatever and whomever’s GPUs they want. And lastly, they don’t want to pay for – or wait for – expensive supply chain-constrained high-speed networking to feed those GPUs. GigaIO addresses all these requirements head-on.
We Also Look Like the Cloud Platform of the Future
Organizations that are seeking GigaIO out are extremely tech savvy. They know where technology is heading and they know it will be made of multirack-scale disaggregated “servers’ like Google Cloud Platform’s Aquila Concept for example. The paper cited in the link is quite telling. Here is the first sentence of the abstract: “Datacenter workloads have evolved from the data-intensive, loosely-coupled workloads of the past decade to more tightly coupled ones, wherein ultra-low latency communication is essential for resource disaggregation over the network and to enable emerging programming models.” They should know.
Here is GCP’s stated design goal with Aquila which is essentially similar to GigaIO’s FabreX

Google’s Branding Even Makes It Into GCP Tech Presentations
GCP implemented Aquila by using a novel L2 Protocol, GNet, and an integrated switch and NIC ASIC, that GCP calls ToR-in-NIC (TiN). This is similar to GigaIO’s FabreX TOR Fabric Switch, except GigaIO uses industry standard PCIe to implement the ultra-low latency unified fabric.
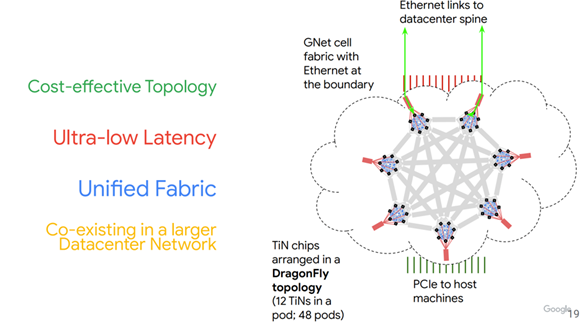
GCP Aquila Architecture
And here is how GigaIO does it. See how similar in concept they are and why those in the know are so interested in GigaIO?
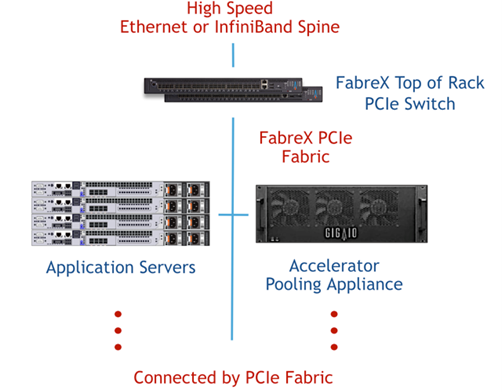
GigaIO FabreX Architecture
So, if at your next trade show, you see a GigaIO person in intense conversation with someone, know they are likely from an organization doing very consequential work looking for the best architecture to repatriate their critical workloads running expensively in the cloud – onto the most advanced ultra low-latency, disaggregated computing technology available today.
And if you are interested in learning more about this trend, drop us a line at info@gigaio.com.


