Beyond the Box: Scaling GPUs
Note: This article originally appeared on hpcwire.com, click here to read the original piece.
November 14, 2023
The performance of GigaIO’s SuperNODE™ was described in a previous HPCWire article. Accessing 32 GPUs or accelerators (from any vendor) over a shared PCI bus provides a unique method for application acceleration. Recently, the SuperNODE received a 2023 HPCwire Editors’ Choice Award for Best AI Product or Technology and made the Editors’ Top 5 New Products or Technologies to Watch list.
Most commercial motherboards allow four (and sometimes eight) GPU cards on the local PCIe bus. The GigaIO SuperNode takes this to a new level using their FabreX network; they can present 32 (and now 64) GPUs to the host processor. FabreX provides the ability to create composable systems that allocate PCIe devices across multiple servers.
GigaIO has shared recent benchmarks for the new 32 GPU SuperNODE and the just announced 64 GPU SuperDuperNODE. The system used for the benchmarks contained 32 or 64 AMD Instinct™ MI210 GPUs connected over GigaIO FabreX™to a 1U server with dual AMD EPYC™ Milan.
GigaIO’s SuperNODE system was tested with 32 AMD Instinct MI210 accelerators on a Supermicro 1U server powered by dual 3rd Gen AMD EPYC processors. The first set of benchmarks used Hashcat and Resnet 50.
- Hashcat: Workloads that utilize GPUs independently, such as Hashcat, should scale perfectly linearly to the 32 GPUs tested.
- Resnet 50: For workloads that utilize GPU Direct RDMA or peer-to-peer, such as Resnet50, the scale factor should be slightly reduced as the GPU count rises.
The results in Figures One and Two show the scalability of the 32 GPU SuperNODE. The results demonstrate significantly improved scalability for ResNet 50 compared to the legacy alternative of scaling the number of GPUs using multiple servers and MPI to communicate between individual nodes. Benchmarks indicate that when testing a multi-node MPI model, GPU scalability is reduced to 50 percent or less.
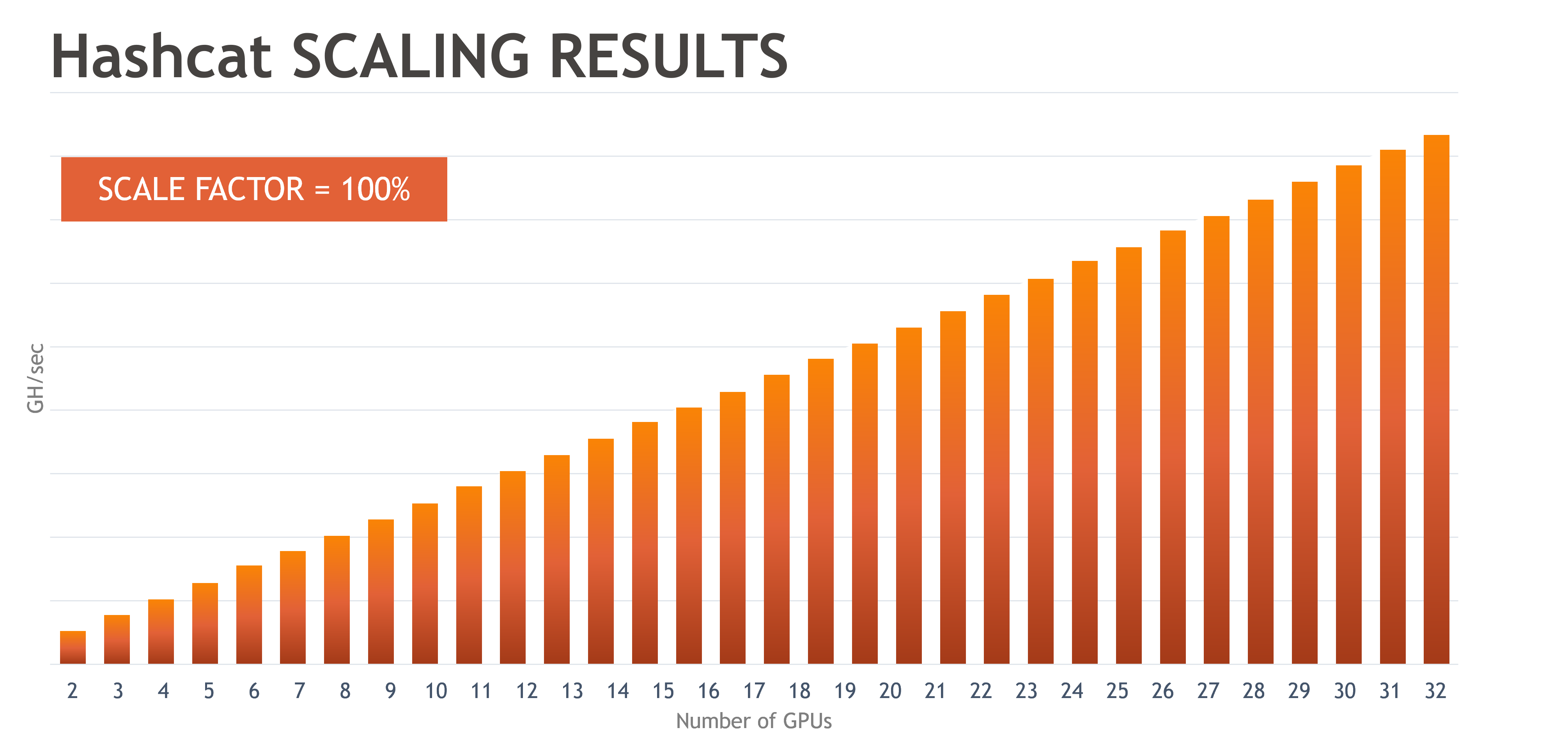
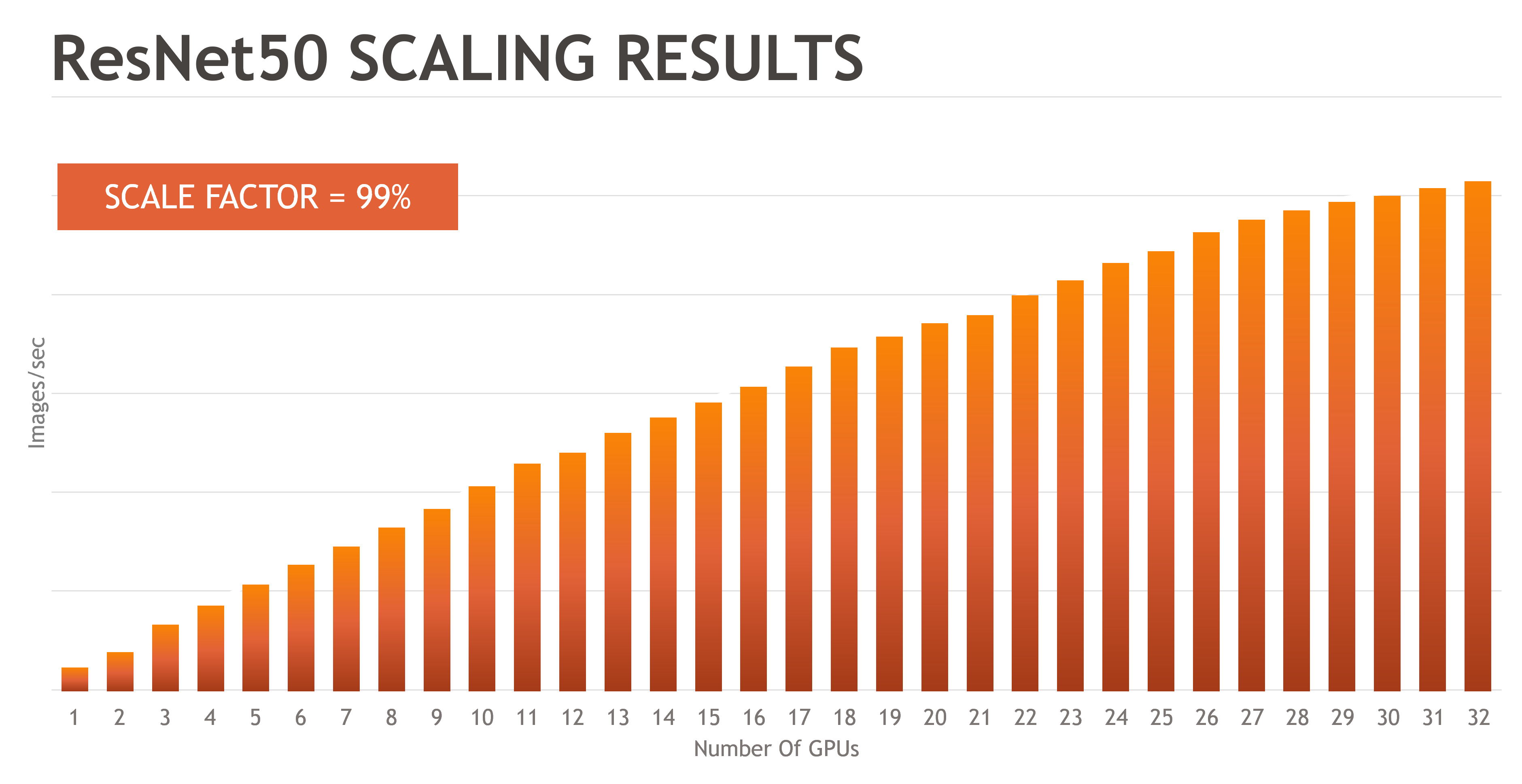
Double the GPUs
The scalability of the 32 GPU SuperNode demonstrated exceptional performance and scaling. The SuperDuperNode brings 64 GPUs to the single server. Many HPC users look to the Top500 benchmarks to measure system performance. Several HPC benchmarks were used to test the SuperDuperNODE performance.
- HPL-MxP – measures the mixed precision type of workload used in high-performance computing (HPC) and artificial intelligence (AI) workloads.
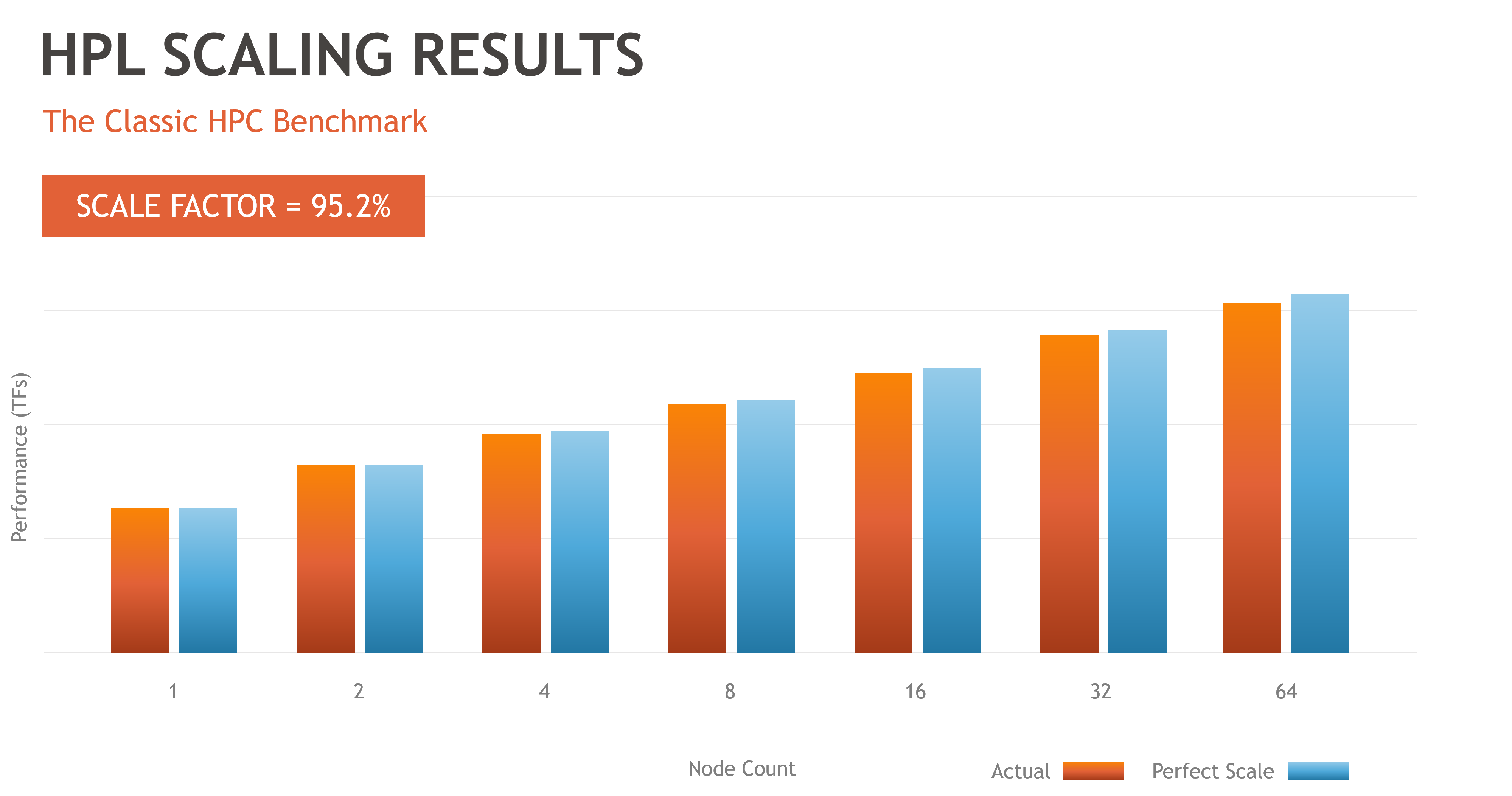
- HPL – solves a (random) dense linear system in double precision (64 bits) arithmetic (used for Top500 ranking)
- HPCG – solves a Conjugate Gradient problem and stresses various aspects of the system, particularly memory performance.
Results for HPC-MxP
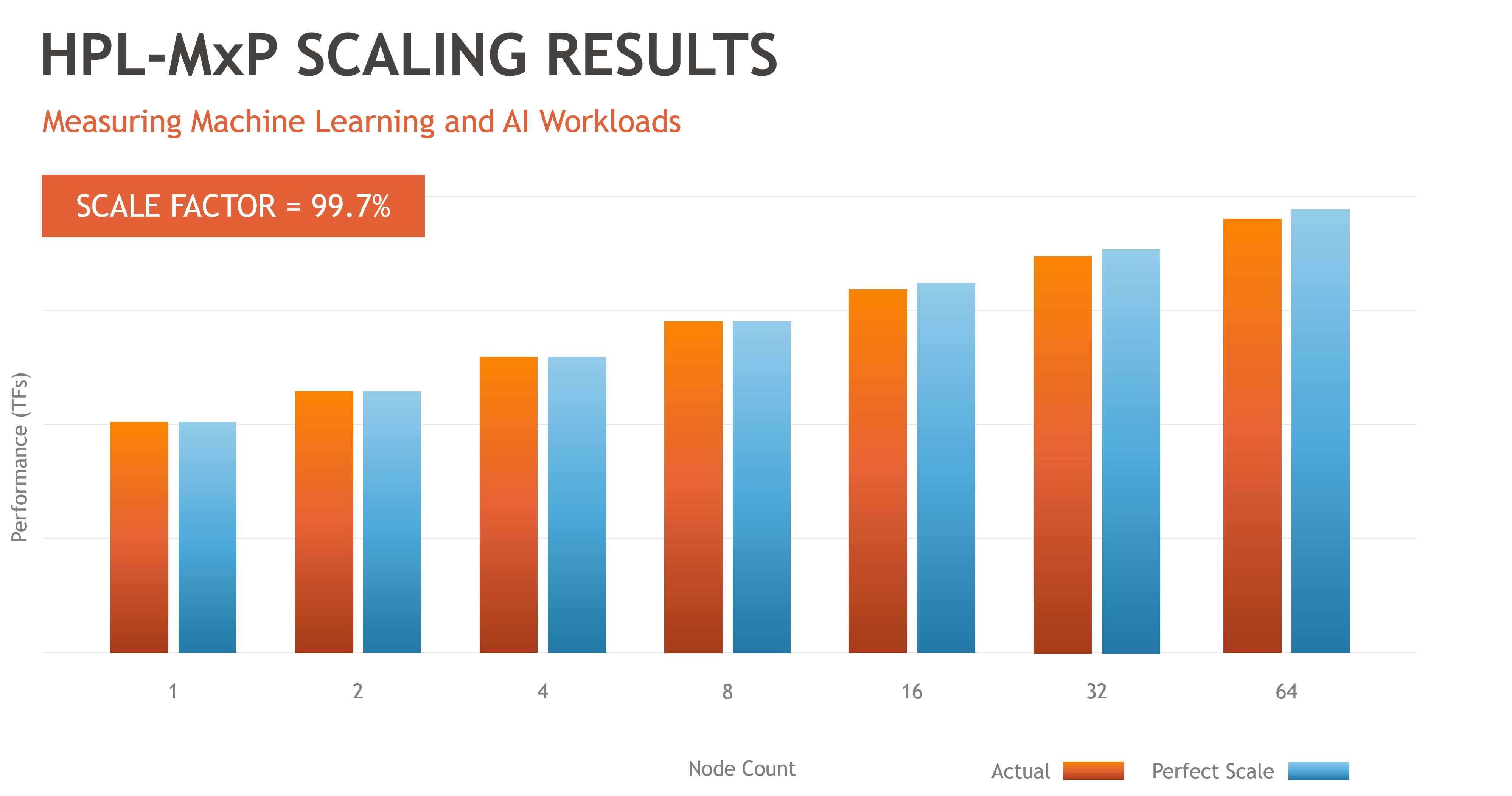
As shown in Figure three, the results for the HPL-MxP benchmark showed excellent scaling for reduced precision computes bandwidth, achieving 99.7% of ideal theoretical scaling.
Results for HPL
Results for the Top500 HPL benchmark resulted in 95.2% of ideal theoretical scaling. For parallel systems, the inter-node networks directly affect scalability (a slower network results in poor scalability)
Results for HPCG
The HPCG benchmark showed 88% scaling, an excellent result for memory scaling.
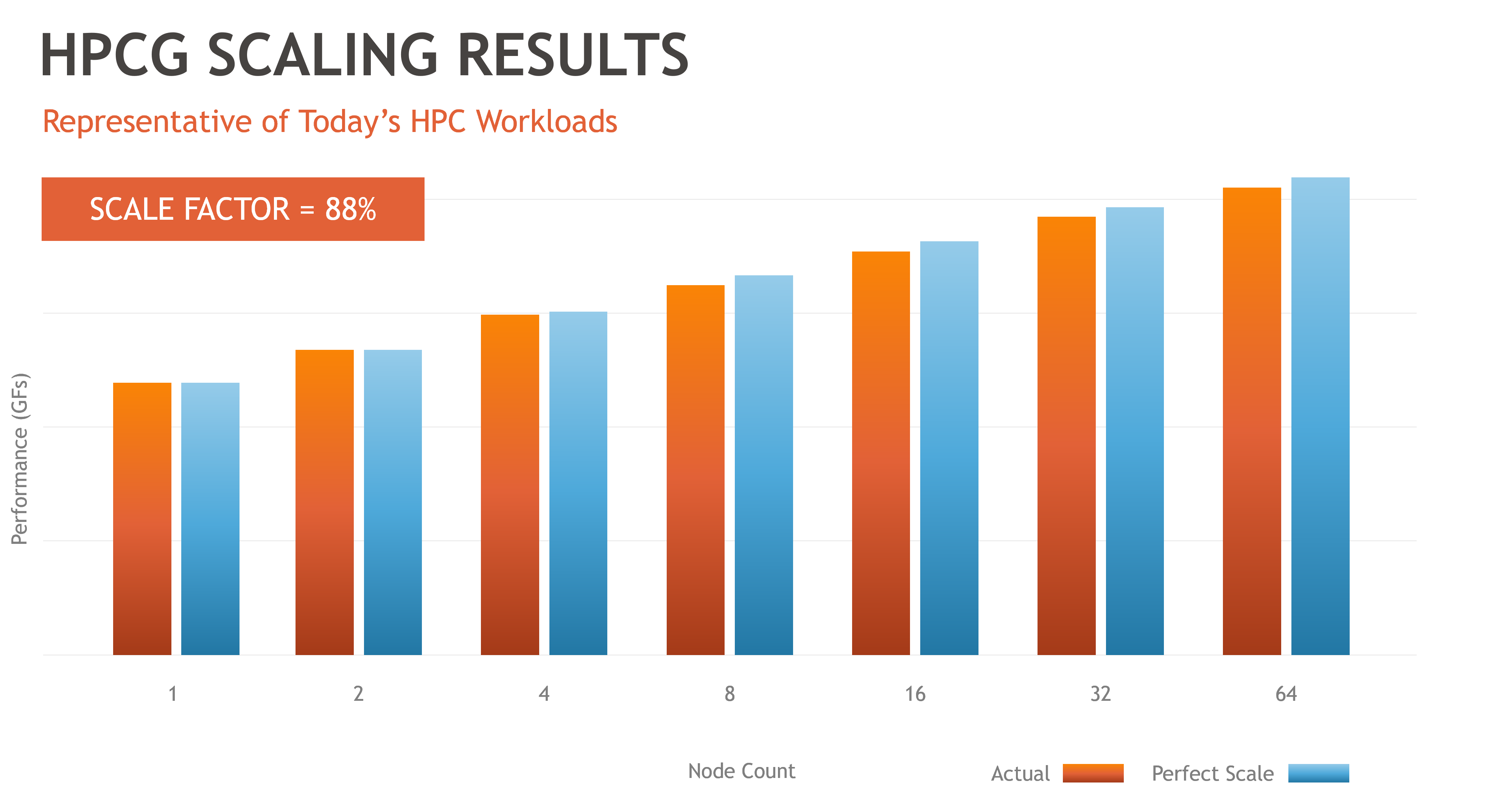
These results demonstrate significantly improved scalability compared to the legacy alternative of scaling the number of GPUs using MPI to communicate between multiple nodes. For example, to apply 64 GPUs to an HPC problem, a user would need sixteen 4-GPU servers connected to a high-speed network. When running benchmarks in this configuration, the GPU scalability is often reduced by 50 percent or less. In other words, half of the GPU computing performance is unavailable to the application.
View source version on hpcwire.com: https://www.hpcwire.com/2023/11/14/beyond-the-box-scaling-gpus/


")